fragment 的碎碎念
GraphQL 大家都不再陌生了,很多技术前瞻(作死)的公司都在用了,其中 fragment 作为一个 feature 我觉得很有必要单独拿出来说道说道。GraphQL 作为一种查询语言,从 OOP 的思想来看,fragment 可以看作是这个语言的 class ,也就是对一个具有相同属性的对象的定义。然后就可以多处引用,而无需多次编写。一个基本的 fragment 用起来形如下:
1 | query ComparisonQuery{ |
作为对比,不使用 fragment 的查询如下:
1 | query ComparisonQuery{ |
看起来差别不大,也就多写了 5 行查询代码,但实际上编译后生成的代码的区别是很大的。生成后的代码太长我就不贴了,直接看一下区别:
| 区别 | 使用 fragment | 不使用 fragment |
|---|---|---|
| Character 类数量 | 1 | 2 |
| Friend 类数量 | 1 | 2 |
主要起影响的就这两点,虽然两种写法查询返回的数据格式和内容不会有任何区别,但有过实践经验的同学肯定明白这两点区别的重要性:
首先 2 个
Character类,即LeftComparsion.Character和RightComparsion.Character,它们都是ComparsionQuery.java的内部类。虽然它们拥有相同的属性,但实际上,它们不是同一个类。 也就是这两个类的实例是不能划等号的,也不是继承关系,不能放在一个集合里。然后是 2 个 Friend 类,即
LeftComparsion.Character.Friend和RightComparsion.Character.Friend。这是 2 个嵌套内部类,同样的,不能划等号,不能放在一个集合里。还有一个更大的坑,如果
appearsIn这个属性不是一个基本属性,也是一个自定义的类,那么这个类也会生成 2 个,影响与以上 2 点相同。
LeftComparsion和RightComparsion是必然会生成的 2 个类,无论是否使用 fragment,这是我当前使用的 Android 平台的 GraphQL 框架特性所决定的,也就是 ApolloAndroid。
不能做比较,不能放在一个集合里,除非这两个类都只是用来简单的显示,不会有任何的交叉计算,否则这已经是无法正常使用的情况了。
所以,为了使用方便,多个查询文件里相同对象的声明,最好在全局只有一次,上例中使用了 fragment 的方式,其内所涉及的类都只会生成一个,是可以互相比较和集合处理的。
将 fragment 定义在独立文件中
你以为生成重复类的问题这样就可以避免了吗?如果你在 另一个查询文件中也涉及到了某个已经声明的 fragment ,那么这个 fragment 的声明全局也会重复,它们都是各自对象的 XXXXQuery.java 的内部类。当你使用的时候,IDE 会提示你有两个同样的类,那么该使用哪种呢?我想你肯定也不行想面对这样艰难的选择,那么就一定要记得:会出现在多个查询文件中的对象,一定要有独立的声明。 什么意思呢,也就是你需要新建一个 CharacterFragment.graphql 文件,在其中只放入对 Character 的声明:
1 | fragment comparisonFields on Character { |
然后把其他所有查询文件中对 Character 的声明统统删掉,改成对 comparisonFields 的引用,然后编译,全局就只有 comparisonFields 这一个 Character 的类了。清爽!
如果你不想每多一个类就新增一个 graphql 文件,那你也可以只增加一个文件Fragments.graphql 来存放所有的 Fragment 的声明。
这样一来,所有的 fragment 都只会有一个声明,使用起来绝对是顺手很多了。
注意,Graphql 中的枚举类不存在重复的情况,全局也只会有一个声明。因为枚举不需要我们来做声明。
需要参数的 fragment
按照上面所说,将 fragment 定义在独立的 graphql 文件中,但如果 fragment 中某个属性需要传递参数,该如何处理呢?首先看一下不使用 fragment 的前提下如何向一个内部对象传递参数:
1 | query ComparisonQuery($episode:ID $picked:Boolean){ |
直觉告诉我们会跟声明一个查询文件一样,也就是需要在头部声明参数名和参数类型,那么是这样吗:
1 | query ComparisonQuery($episode:ID $picked:Boolean){ |
此时你编译肯定会失败,实际上无需多次定义和传递这么麻烦,只需要如下即可:
1 | query ComparisonQuery($episode:ID $picked:Boolean){ |
同样,如果是独立定义的 fragment ,也只需把 fragment 声明的这一坨拿出来放在独立的文件里就可以了。
为什么看起来只是把 Character 的声明拿出来就可以了呢?实际上就只是这么简单。如果你对 graphql 的请求抓包,你会发现无论你如何声明 fragment ,只要是语法所允许的,最后发出的请求中 fragment 的引用都会被 fragment 的声明所替换,也就是实际发出的请求里真实的查询语句就是没有使用 fragment 的样子,这是编译框架自动帮我们做的事情。而我们需要做的,就是把查询文件内所有需要的参数,在查询入口处声明即可,也就是每个 query 文件的第一行进行声明,例如本例中 query ComparisonQuery($episode:ID $picked:Boolean) 的形式。
并列式 fragment
Graphql 中有一个比较特殊的 feature 叫做 MetaUnion ,也叫联合类型。一般是用于同一个大类下的不同子类,不同于我们在 OOP 语言中所说的子类是继承于某个类的类。Graphql 中的 MetaUnion 实际上只是一个关键字,表示其内可能存在多个类型,一般都是结构相似、基本属性相似但是略有区别的对象,一般用于 Feed 流中。最常见的就是聊天记录中,多种类型的消息了,例如:
一般的语言系统中,其实际的关系会是这种结构:
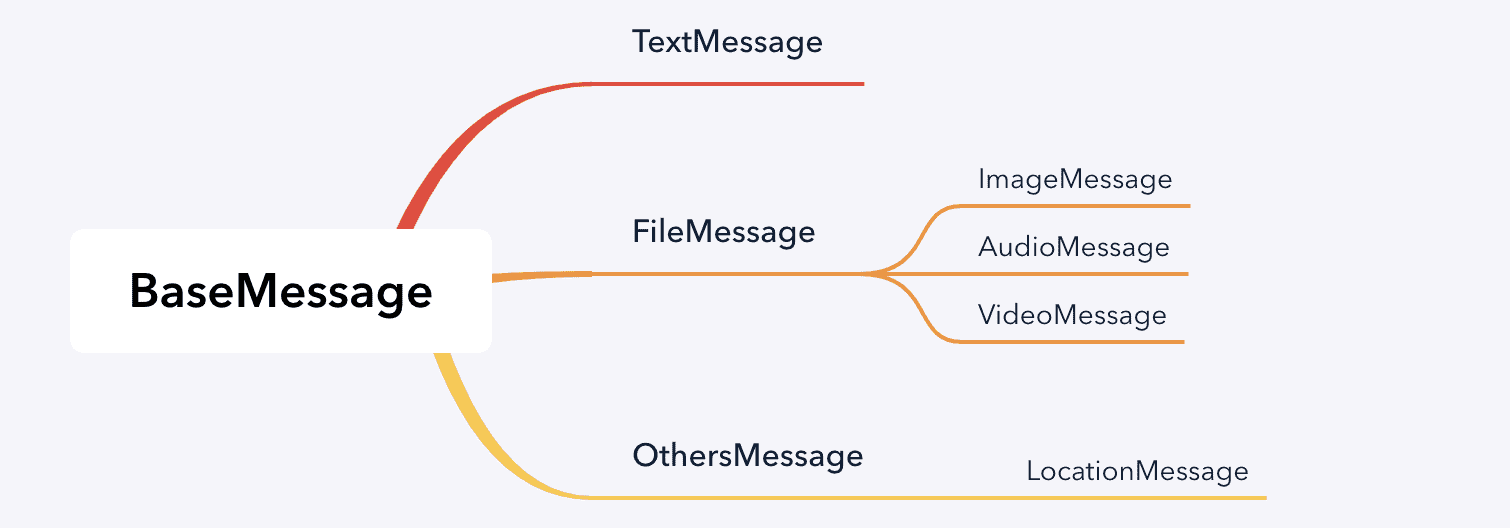
但在 Graphql 中,所有消息类型都是平级的,不存在继承关系,虽然它们有公共属性,但非公共的属性都会在 MetaUnion 中,体现在 graphql 中:
1 | query MessageQuery($userId:ID! $conversitionId:ID!){ |
这里简单起见,我只在 metadata 中写了 2 个类型。实际生产中需要写当前所有可能出现的类型,如果是 MVP 发布,第一期只支持 Text 消息,则可以只写 TextMessageField 一个引用,但需要在接口返回值中过滤掉不支持的消息类型,或者使用通用的提示进行替代。
可以看到 metadata 中同时引用了 2 个 fragment 声明,因为其可能返回的类型存在多种情况,而 metadata 之外的属性,就是所有 Message 类型的公共属性了。根据公共属性 messageType 可以知道该消息的类型,然后分别去拿 metadata 中对应 fragment 的数据按照不同的 UI 进行展示。
除了 MetaUnion 中可以使用并列式 fragment 引用,非 MetaUnion 也可以使用并列式 fragment 引用。
定义一个对象:
- Clazz
- id
- name
- studentsCount
- teachers
- id
- name
- students
- id
- name
- gender
- age
我们知道 Graphql 一个好处就是可以自由查询所需要的信息,不需要的可以不查,那么就有了一个约定:不需要的信息尽量不查询,以减轻服务端的压力。
可是按照前文所说,每个对象类型只能声明一次,那么不需要的属性也一起被声明了,所以还是会存在查询了不需要的信息的情况,造成了服务端的资源浪费。不用担心,我们可以进行多重声明。也就是如下形式的声明:
1 | fragment BaseClazz on Clazz{ |
我们可以将 Clazz 的属性分别声明在 3 个 fragment 中,当我们只需要班级基本信息的时候,只需要如下查询:
1 | query BaseClazzInfo(clazzId:ID!){ |
如果还需要学生信息和老师信息:
1 | query FullClazzInfo(clazzId:ID!){ |
按照使用信息的需求,添加对应属性 fragment 的声明,就可以拿到对应的数据,若仅需基本信息,则仅引用 BaseClazz 即可。一般来说,没有必要将对象的每个属性进行单独声明,根据不同的查询压力、计算量,将某个对象分成多个 fragment 进行声明。在这个例子中,Clazz 的基本信息、学生信息、教师信息分属 3 张表,查询压力明显不同,所以这样分是比较科学的。如果 studentsCount 不是直接写在 Clazz 表里,而是实时计算的,那么便可以将该属性单独声明一个 fragment,当不需要该属性的时候,可以不引用,这样的分别声明在数据量比较大的时候可以节省下相当多的服务器计算资源。
嵌套式 fragment
并列式 fragment 引用的确有存在的价值,但也带来的一个弊端:它将一个对象分割成多份,当我们需要一个相对完整的对象的时候,无法仅通过一个对象来表示,这在实际开发的时候是极为不方便的。所以就有了嵌套式 fragment 引用,还是上面那个例子,也是分割开来进行声明,但是声明方式有所不同:
1 | fragment BaseClazz on Clazz{ |
来看嵌套式 fragment 引用的写法:
1 | query ClazzInfo(clazzId:ID!){ |
同一个类型的声明是可以嵌套引用的,以上 ClazzTeachers 和 ClazzStudents 在 FullClazzInfo 中同时引用了 BaseClazz ,所以存在几个属性的重复,但是没关系,在生成实际的请求文件的时候,会自动进行去重处理,而当你使用数据的时候,你可以通过 ClazzTeacher、ClazzStudents 任意一个获取到 BaseClazz 信息。现在,就可以通过 FullClazzInfo 获取到 Clazz 的全部信息了。
通过嵌套声明和引用的方式,我们既解决了按需查询的问题,又解决了对象被割裂的问题。当然也不是没有缺点,一个就是需要按照使用需要做不同的嵌套和组合;另一个就是嵌套深度变多,实际使用的时候就是大型流式 API 秀场了,因为嵌套式引用在编译后,嵌套引用的 fragment 会自动成为一个内部属性,而 ApolloAndroid 的特性本来就会为 fragment 增加一层嵌套深度,如果想通过 FullClazzInfo 拿到 clazz 的 id 属性,就需要:
1 | val clazzId = FullClazzQuery.Data() |
的确是相当的麻烦,不过相比使用上的阻碍和资源的损耗,写法上的冗余也是可以接受的。况且这是框架特性所导致的,随着框架的迭代更新这个问题或许可以被解决,但使用上的阻碍和节约的资源是现在就能立刻就能享受到的好处。
内联式 fragment (Inline fragment)
在上面所提到的联合类型查询的时候,可以使用并列式 fragment, 其实也可以用另外一种方式:内联式 fragment 。这是一种具体对象具体查询的方式,通俗讲就是谁有某个属性,就找谁要。 还是看一个上面消息的例子:
1 | query MessageQuery($userId:ID! $conversitionId:ID!){ |
如果查到的是一个 TextMessage, 实际上返回值如下:1
2
3
4
5
6
7
8
9
10{
"data": {
"messages": [{
"id" : "1",
"messageType" : "Text",
"content" : "this is message content",
""
}]
}
}
如果查到的是一个 ImageMessage, 实际上返回值如下:1
2
3
4
5
6
7
8
9
10
11{
"data": {
"messages" : [{
"id" : "2",
"messageType" : "Text",
"url" : "https://www.baidu.com/img/bd_logo1.png",
"width" : 400,
"height" : 200
}]
}
}
我们看到,无论实际查到的是什么类型,与基本属性一样,都包含在同一个对象里面,于是从返回的 json 字符串上来看,一切都很美好, 但是实际生成 java 代码后,你会发现可能现实与你想象的还有点距离。为什么这么说,看一下实际生成的 Metadata 的 Java 代码:
1 | public interface Metadata { |
这里我我只截取了比较关键的的代码, 不过也能看得出, Metadata 其实只是一个接口,而 2 中消息都是这个接口的具体实现,我们看到 json 里 Message 的属性都在一个对象里,而生成的 Java 代码中这些属性也确实都是一个一个对象(metadata)里, 但是我们并不知道具体的实现类是什么,如果 metada 外面没有一个属性来指明 metadata 具体是什么,拿么只有通过类型判断才能知道了:
1 | if(meatadata instanceof AsTextMessage){ |
明白了这种使用的方式,就可以进一步替换成 Inline frsgment 了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15query MessageQuery($userId:ID! $conversitionId:ID!){
messages(userId:$userId conversitionId:$conversitionId){
id
messageType
happenedAt
metadata{
... on TextMessage{
... TextMessgaeField
}
... ImageMessage{
... ImageMessageField
}
}
}
}
当然还记得我上面提到的, 使用 fragment 会增加一层嵌套,也就是要通过:1
((AsTextMessage)metadata).fragment.textMessageField.content
来获取消息内容了。这样的使用方式,其实还是很难受的。所以我很不喜欢这种内联式的 fragment 用法。
小结
其实以上 fragment 的用法在 json 这个层面来看都是非常实用的,我们只要记得,所有 fragment 的声明,在最后请求发出的时候都会被声明的内容所替换,也就是发出的请求中是不会包含 fragment 这个关键字的,那么通过以上 fragment 用法的多种组合,我们可以很灵活的实现不同的查询需求,graphql 本身的语法糖是很优秀的,而最大的阻碍其实还是 graphql 在 Android 的编译插件的缺陷,会极大地增加使用成本,而且学习起来也较有难度,希望在未来 ApolloAndroid 这个编译插件能够越来越简洁,性能越来越强大,也寄托于第三方能够实现更好的原生平台编译插件。
参考文档
文中所写都基于本人实际经验,如有错误,欢迎指正。